|
PieAPP: Perceptual Image-Error Assessment through Pairwise Preference |
| Proceedings of The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018. |
|
|

Abstract
The ability to estimate the perceptual error between images is an important problem in computer vision with many applications. Although it has been studied extensively, however, no method currently exists that can robustly predict visual differences like humans. Some previous approaches used hand-coded models, but they fail to model the complexity of the human visual system. Others used machine learning to train models on human-labeled datasets, but creating large, high-quality datasets is difficult because people are unable to assign consistent error labels to distorted images. In this paper, we present PieAPP, a metric that predicts perceptual error of a distorted image with respect to a reference in a manner consistent with human observers.
Since it is much easier for people to compare two given images and identify the one more similar to a reference than to assign quality scores to each, we propose a new, large-scale dataset labeled with the probability that humans will prefer one image over another. We then train a deep-learning model using a novel, pairwise-learning framework to predict the preference of one distorted image over the other. Our key observation is that our trained network can then be used separately with only one distorted image and a reference to predict its perceptual error, without ever being trained on explicit human perceptual-error labels. The perceptual error estimated by PieAPP is well-correlated with human opinion. Furthermore, it significantly outperforms existing algorithms, while also generalizing to new kinds of distortions, unlike previous learning-based methods.
Paper and Additional Resources to try PieAPPv0.1
Technical details about PieAPPv0.1:
Try out PieAPPv0.1:
Try out the PieAPP dataset:
Performance Evaluation
| Method | KRCC | PLCC | SRCC | |
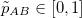 |
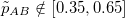 |
|||
| MAPE | 0.233 | 0.278 | 0.170 | 0.290 |
| MRSE | 0.185 | 0.211 | 0.135 | 0.219 |
| NQM | 0.216 | 0.234 | 0.508 | 0.246 |
| IFC | 0.165 | 0.178 | 0.230 | 0.198 |
| VIF | 0.179 | 0.192 | 0.250 | 0.212 |
| MAD | 0.270 | 0.301 | 0.231 | 0.304 |
| RFSIM | 0.217 | 0.246 | 0.368 | 0.247 |
| GSM | 0.324 | 0.376 | 0.356 | 0.378 |
| SR-SIM | 0.296 | 0.356 | 0.352 | 0.358 |
| MDSI | 0.280 | 0.336 | 0.349 | 0.350 |
| MAE | 0.252 | 0.289 | 0.302 | 0.302 |
| RMSE | 0.289 | 0.339 | 0.324 | 0.351 |
| SSIM | 0.272 | 0.323 | 0.245 | 0.316 |
| MS-SSIM | 0.275 | 0.325 | 0.051 | 0.321 |
| GMSD | 0.250 | 0.291 | 0.242 | 0.297 |
| PSNR-HMA | 0.245 | 0.274 | 0.310 | 0.281 |
| FSIMc | 0.322 | 0.377 | 0.481 | 0.378 |
| SFF | 0.258 | 0.295 | 0.025 | 0.305 |
| SCQI | 0.303 | 0.364 | 0.267 | 0.360 |
| DOG-SSIMc | 0.263 | 0.320 | 0.417 | 0.464 |
| Lukin et al. | 0.290 | 0.396 | 0.496 | 0.386 |
| Kim et al. (CVPR 2017) | 0.211 | 0.240 | 0.172 | 0.252 |
| Bosse et al. NR (TIP 2018) | 0.269 | 0.353 | 0.439 | 0.352 |
| Bosse et al. FR (TIP 2018) | 0.414 | 0.503 | 0.568 | 0.537 |
| LPIPS: VGG-lin (CVPR 2018) | 0.503 | 0.625 | 0.654 | 0.641 |
| LPIPS: Alex-lin (CVPR 2018) | 0.485 | 0.601 | 0.644 | 0.625 |
| LPIPS: Squeeze-lin (CVPR 2018) | 0.500 | 0.624 | 0.678 | 0.647 |
| PieAPPv0.1 (CVPR 2018) | 0.668 | 0.815 | 0.842 | 0.831 |
We evaluate the performance of popular and state-of-the-art approaches for image error or quality prediction on our proposed test set, using Kendall, Pearson, and Spearman correlation coefficients (KRCC, PLCC, and SRCC respectively in the table above). This test set is completely disjoint from our proposed training set in terms of reference images and distortion types (total 40 test reference images and 31 test distortion types). This enables us to evaluate the generalizability of the learning-based approaches to unseen distortion types and images. More details can be found in our paper and supplementary document.
Bibtex
@InProceedings{Prashnani_2018_CVPR,
author = {Prashnani, Ekta and Cai, Hong and Mostofi, Yasamin and Sen, Pradeep},
title = {PieAPP: Perceptual Image-Error Assessment Through Pairwise Preference},
booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2018}
}
Acknowledgements
This project was supported in part by NSF grants IIS-1321168 and IIS-1619376, as well as a Fall 2017 AI Grant (awarded to Ekta Prashnani).